打造高效数据中台,如何搭建元数据管理中心
2024/6/14
01元数据概述
1.1 元数据定义
元数据(Metadata)又称中介数据、中继数据,是描述数据的数据(data about data),主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
数据中台的构建,需要确保全局标准的业务口径一致,要把原先口径不一致的、重复的指标进行梳理,整合成一个统一的指标字典。而这项工作的前提,是要搞清楚这些指标的业务口径、数据来源和计算逻辑。而这些数据都属于元数据。
1.2 元数据分类
元数据主要分为数据字典、数据血缘和数据特征三类。
1.数据字典:描述数据的结构信息,表结构信息,主要包括:表名,字段名,类型和注释,表的数据产出任务,表和字段的权限等。
2.数据血缘:指一个表是通过哪些表的加工而来,数据血缘会进行影响分析和故障溯源。
3.数据特征:主要指数据的属性信息:存储空间大小,数仓分层,访问热度,主题分类,关联指导等。

02 构建元数据中心的关键目标
元数据中心作为数据管理和治理的核心组件,其设计和实施需围绕几个关键目标展开,以确保能够有效地支持企业数据战略。以下是元数据中心的五个关键目标:
1.多业务线与多租户支持
元数据中心需具备高度灵活性,以支持不同业务线(如电商、金融、物流等)的独特数据需求。同时,它应提供多租户架构,确保不同部门或团队(如算法、数仓、风控)在共享元数据资源的同时,保持数据的安全隔离和访问控制。
2.数据资产管理:
实现企业数据资产的全面可视化,包括数据源、数据流、数据质量、数据血缘等,以便于跟踪数据的生命周期,提升数据的可发现性和可追溯性。
3.数据标准化与规范化:
建立统一的数据标准和规范,包括数据定义、命名规则、编码体系等,减少数据冗余,提高数据一致性,为数据分析和业务决策提供准确的基础。
4.数据治理与合规性:
强化数据治理能力,包括数据质量监控、数据安全管控、合规性检查等,确保数据处理活动符合内外部的法规要求(如GDPR、HIPAA等),降低合规风险。
5.促进数据共享与协作:
通过提供数据目录、API服务、数据字典等功能,促进跨部门、跨系统的数据共享和协同工作,加速数据驱动的业务创新和决策过程。
这五个目标相互关联,共同构成了元数据中心的核心价值主张,即通过高效的数据管理和治理,提升数据价值,加速企业数字化转型的进程。
03 元数据技术
3.1 开源产品
元数据中心的优秀产品主要包括:Netflix的Metacat、Apache的Atlas;
其中,Metacat是多元数据的可扩展架构,擅长数据字典管理,Atlas擅长数据血缘。
1.Metacat
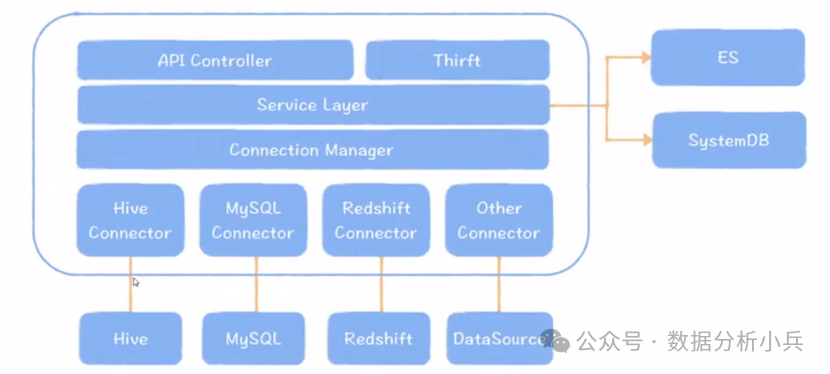
特点:设计极简,并不会重复保存元数据,而是采取直连数据源的方式,因此不会存储重复保存元数据造成的数据一致性问题,同时架构能做到极致的轻量化,每个数据源只要实现一个链接类即可。
2.Atlas
数据采集可以分为三种形式
(1)通过静态SQL、获得输入表和输出表;但是由于任务没有执行,存在准确性问题;
(2)通过抓取正在执行的SQL、解析执行计划,获得输入表和输出表;最为理想的方式;
(3)通过任务日志解析,获取执行后的SQL输入表和输出表;血缘虽然是在执行后产生的,可以保证准确性,但是存在时效性的问题。
因此Atlas采取的就是通过抓取正在执行的SQL、解析执行计划,获得输入表和输出表的方法。
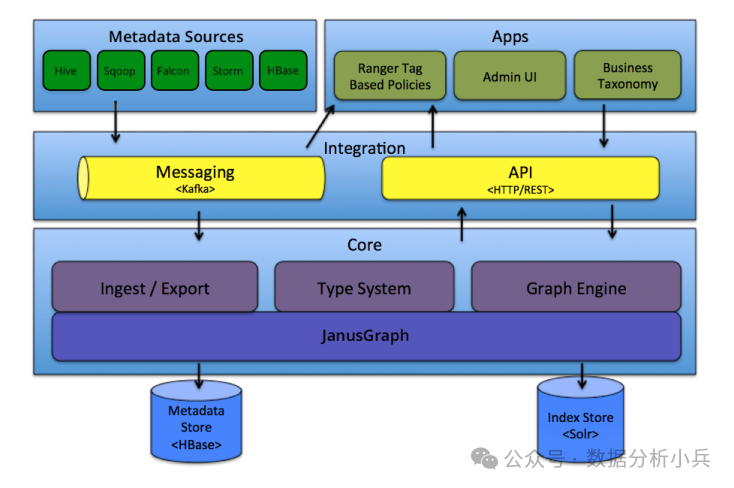
Core核心层:
•Ingest / Export:Ingest组件将元数据添加到Atlas。同样,Export组件公开Atlas检测到的元数据更改,并将其作为事件引发。用户可以使用这些更改事件来实时响应元数据更改。
•Type System类型系统:Atlas允许用户为他们想要管理的元数据对象定义模型。该模型由称为“类型”的定义组成。称为“实体”的“类型”实例代表了被管理的实际元数据对象。类型系统是一个允许用户定义和管理类型和实体的组件。开箱即用的Atlas管理的所有元数据对象(例如Hive表)都使用类型建模并表示为实体。
•Graph Engine图引擎:在内部,Atlas使用图模型持久化管理的元数据对象。这种方法提供了极大的灵活性,并能够有效地处理元数据对象之间的丰富关系。图形引擎组件负责Atlas类型系统的类型和实体之间的转换,以及底层图形持久化模型。除了管理图形对象外,图形引擎还为元数据对象创建适当的索引,以便可以有效地搜索它们。Atlas使用JanusGraph来存储元数据对象。
Integration消息传递层
用户可以使用以下两种方法管理Atlas中的元数据。
•Messaging消息传递:用户可以选择使用基于Kafka的消息传递接口与Atlas集成。Atlas使用Apache Kafka作为通知服务器,用于挂钩和元数据通知事件的下游消费者之间的通信。事件由钩子和Atlas写入不同的Katka主题。
•API:Atlas的所有功能都通过REST API公开给最终用户,该API允许创建、更新和删除类型和实体。它也是查询和发现Atlas管理的类型和实体的主要机制。
Metadata sources元数据源层:
Atlas支持与开箱即用的许多元数据源集成。目前,Atlas支持从以下来源获取和管理元数据:
•HBase
•Hive
•Sqoop
•Storm
•Kafka
Apps应用层:
Atlas管理的元数据被各种应用程序使用,以满足许多治理用例。
•Atlas Admin UI:该组件是一个基于Web的应用程序,允许数据管理员和科学家发现和注释元数据。这里最重要的是搜索界面和类似SQL的查询语言,可用于查询Atlas管理的元数据类型和对象。管理UI使用Atlas的REST API来构建其功能。
•基于标签的策略:Apache Ranger是Hadoop生态系统的高级安全管理解决方案,与各种Hadoop组件广泛集成。通过与Atlas集成,Ranger允许安全管理员定义元数据驱动的安全策略以实现有效治理
3.2商业化产品
商业化产品比较优秀的是Cloudera Navigator,是Cloudera企业数据平台中一个至关重要的组件,定位为一个数据管理工具,专注于数据管理和治理。它为Hadoop和其他大数据生态系统中的数据提供了一个全面的解决方案,旨在帮助企业实现数据的透明度、可追溯性和合规性。
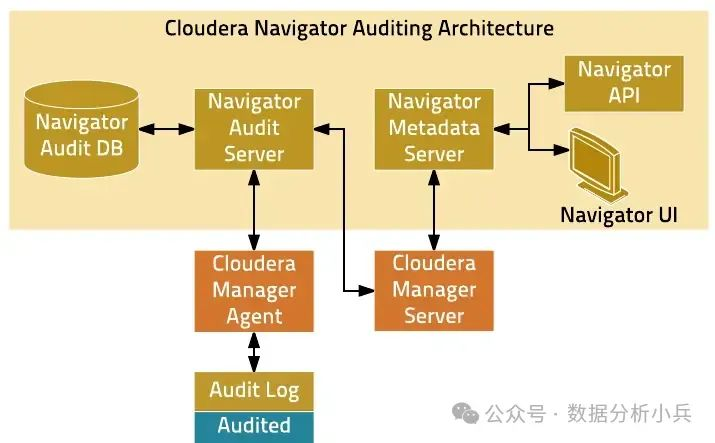
Cloudera Navigator的核心功能主要包括:
数据审计:通过Navigator Audit Server,系统能够记录所有数据相关的活动,包括时间戳、执行操作的用户名、源IP地址、涉及的服务以及具体的操作详情。这为数据安全、合规审计和故障排查提供了详细记录。
元数据管理:Navigator Metadata Server负责收集和管理Hadoop集群中的元数据。它不仅追踪数据的物理位置,还提供数据查询、标签、数据血缘分析等功能,帮助用户理解数据的来源、变换过程和流向,这对于数据质量管理和影响分析至关重要。
数据治理:Cloudera Navigator支持数据分类和政策管理,允许企业根据数据的敏感性和业务规则设置访问控制和保留策略。通过数据标签,用户可以轻松地对数据进行分类和保护,确保数据按照规定的方式被使用和存储。
数据血缘与影响分析:提供可视化的数据血缘图谱,展示数据从源头到最终消费的全过程。这有助于用户理解数据依赖关系,评估变更影响,并在数据质量问题发生时快速定位根源。
搜索与发现:内置的强大搜索引擎使用户能够快速查找数据资产,无论是基于元数据还是审计记录。这大大提升了数据的可发现性和重用性。
集成与自动化:Cloudera Navigator设计有API接口,支持与其他企业系统(如数据目录、BI工具、数据治理平台)集成,实现数据管理任务的自动化。
3.3 元数据中心架构设计
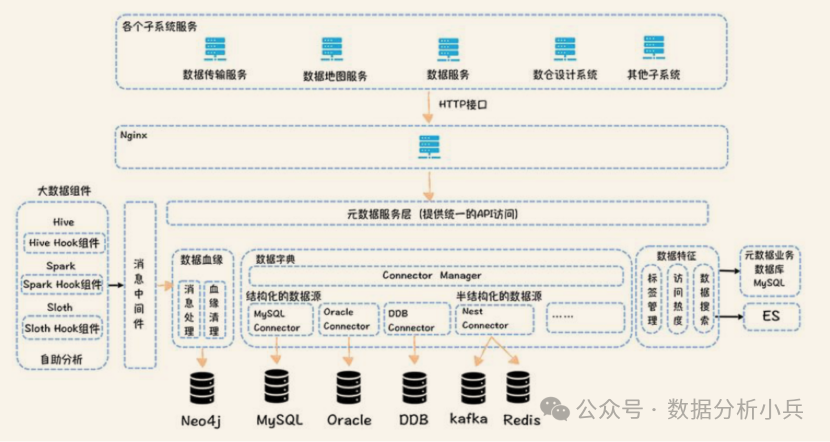
核心部分
1.数据字典:主要采用Metacat从各种数据源中进行数据抓取;
2.数据血缘:从hive,spark等大数据组件中获取数据,通过在平台中嵌入钩子(HOOK)的形式,实时的获取HIVE等实时执行的SQL,针对抓取到的数据进行数据血缘分析,之后将分析结果存储在图数据库中。常见的图数据库有NEo4j(不常用,没有ha机制);
3.数据特征:等价于用户行为分析系统,该模块需要单独针对客户业务行为展开,没有特定的技术体系。
元数据中心统一对外提供了API访问接口,数据传输、数据地图、数据服务等其他的子系统都可以通过API接口获取元数据,另外Ranger可以基于元数据中心提供的API接口,获取标签对应的表,然后根据标签更新表对应的权限,实现基于标签的权限控制。
3.4 元数据中心设计要点
元数据中心是数据中台的基石,它提供了我们做数据治理的必须的数据支撑,数据的指标、模型、质量、成本、安全等的治理,这些都离不开元数据中心的支撑。
1.元数据中心设计上必须注意扩展性,能够支持多个数据源,所以宜采用集成型的设计方式。
2.数据血缘需要支持字段级别的血缘,否则会影响溯源的范围和准确性。
3.数据地图提供了一站式的数据发现服务,解决了检索数据,理解数据的“找数据的需求"。
转载自公众号数据分析小兵


安徽数升数据科技有限公司 版权所有 皖ICP备2021015607号-1 免责声明